


En este episodio de Cloud para Todos veremos una constante batalla por mantenerse actualizado en el mundo del desarrollo de software y el cloud obviamente.

La idea de este episodio surgió desde LinkedIn con una pregunta que leí: ¿Hay diferencia entre un modelo de Machine Learning (ML) y un modelo de IA como un LLM? En este capítulo revelamos una distinción crucial entre procesos predictivos y generativos que muchas organizaciones están pasando por alto al integrar la IA en sus proyectos.
Estando desde hace muchos años acompañando a Devs enfocado en el Software Development Life Cycle (SDLC) (y ahora metido de lleno con la IA), he podido notar que siempre tenemos una batalla que pelear. Y la batalla de hoy me suena muy parecida a una que ya peleamos....
¿Te acuerdas cuando empezó a globalizarse el uso de las herramientas cloud? Todos los Devs venían: Héctor….
¿Cómo hago para tener un usuario? Dame una cuenta para probar mis cosas….
Darle acceso permanente no era la mejor idea. Las instancias quedaban prendidas sin control, bases de datos levantadas sin ningun dueño (si nadie se hacia cargo), y pasaba una factura de 200 dólares a 1000 dólares en una noche.
Bueno, hoy está pasando lo mismo. Pero en lugar de credenciales cloud, los compañeros de equipo preguntan:
¿Qué API Key podemos utilizar para probar con IA?
Entonces viene la gran pregunta, ¿nos pasamos a credenciales de proveedoreso usamos servicios ya existentes? Al estilo de OpenAI, Anthropic, etc. O nos quedamos con AWS Bedrock? Debemos de pensar en el modelo de precios, gobierno, etc.
Y acá es donde debemos de reaccionar...
Antes de empezar: ¿qué necesitas y qué vas a lograr?
Pre-requisitos:
No necesitas ser un experto en IA ni en Machine Learning. Lo que sí necesitas es tener lo básico de tu cuenta de AWS en orden.
AWS Organizations configurado con al menos una OU para tus cuentas de desarrollo
IAM Identity Center (SSO) habilitado, los devs ya deben poder hacer
`aws sso login`Permission Sets creados por equipo (ej:
BackendDev, FrontendDev, QATeam)Amazon Bedrock habilitado en eu-west-1 (o la región que aplique según tu r
gulación)AWS CDK o Terraform para desplegar la infraestructura como código
Conocimientos básicos de IAM Policies, SCPs y CloudWatch: Si ya gestionas cuentas cloud con SSO y policies, ya tienes todo lo que necesitas.
¿Qué vas a lograr al final?
Cuando termines de implementar lo que te voy a mostrar, vas a tener:
Acceso gobernado a LLMs por equipo, Guardrails automáticos, Restricción geográfica, Presupuesto por equipo con corte automático, Dashboard de consumo, Auditoría completa, Reset mensual automático.
Y lo más importante: el developer puede empezar a usar IA desde el día 0 con sus credenciales AWS SSO de siempre, sin esperar a que alguien le consiga una API Key ni pagar nada de su bolsillo.
El problema real: herramientas sin gobierno = caos
Seamos sinceros. No muchas organizaciones tienen reglamentadas estas herramientas. Tenemos a gente copiando y pegando código de clientes en modelos, sin saber las implicaciones que tiene. Cada quien utiliza el IDE (que muchas veces paga de su bolsillo), la que tiene a la mano, o la que puede acceder de forma gratuita.
Ahí hay que tener bastante cuidado.
Ahora, la idea no es controlar. La idea es monitorear y darles herramientas a todos los compañeros para que puedan utilizar la IA de forma segura. Se trata de dar opciones para que puedan sacar el mayor provecho, no de limitar.
¿Y cómo logramos eso desde el día 1?
Resulta que si ya trabajas con AWS, las herramientas ya las tienes. No necesitas desplegar un proxy (por ahora), no necesitas infraestructura adicional. Solo necesitas policies.

El déjà vu: lo que aprendimos del mundo cloud aplica con IA también
Pensemos un momento en cómo resolvimos el acceso cloud. No le dimos a cada dev una AccessKey permanente con permisos de administrador. Aprendimos (a las malas, muchos de nosotros) que lo correcto era:
1. Identity Center (SSO): credenciales temporales, no permanentes
2. IAM Policies: permisos específicos por rol o equipo
3. SCPs: límites a nivel organizacional que nadie puede saltarse
4. AWS Budgets: alertas cuando el gasto se dispara
¿Seguro te suena todo esto no? Porque la estrategia para gobernar el acceso a LLMs es exactamente la misma (casi ya veremos).
Gobierno Cloud vs Gobierno IA Generativa
☁️ Cloud (lo que ya hacemos) 🤖 IA Generativa (lo que necesitamos)
IAM User con access keys Credenciales SSO temporales
Permisos granulares por servicio Permisos granulares por modelo
SCPs para limitar regiones SCPs para limitar regiones + modelos
AWS Budgets para alertar CloudWatch + Lambda para cortar antes del desastre
CloudTrail para auditoría CloudTrail + métricas de tokens
La diferencia es la velocidad. En cloud, un error de costos se nota en días. En IA, un bucle de razonamiento puede gastar 50 dólares en 5 minutos. Por eso necesitamos un mecanismo de corte activo, no solo alertas.
SPOILER:
AWS Budgets no sirve para esto.Ya que tiene una latencia de hasta 24 horas para cortar el acceso, en términos de IA es una eternidad.
Diagrama de lo que estamos creando:
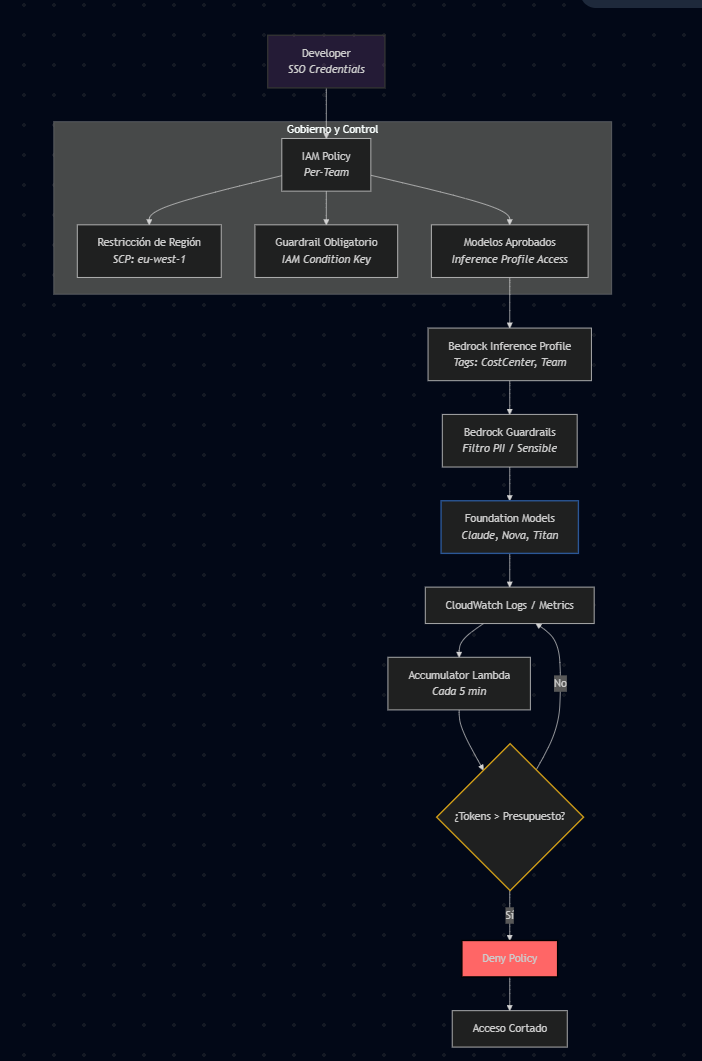
El dev no necesita aprender nada nuevo. Ya sabe hacer aws sso login. Lo único que cambia es que invoca el modelo a través de un Inference Profile de su equipo en lugar del model ID directo.
¿Qué necesitamos configurar?
La IAM Policy del equipo
Esta policy dice: solo puedes usar los modelos de tu equipo, y siempre con AWS Bedrock Guardrail.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowInvokeViaTeamProfile",
"Effect": "Allow",
"Action": ["bedrock:Converse", "bedrock:ConverseStream"],
"Resource": [
"arn:aws:bedrock:eu-west-1:123456789012:inference-profile/team-*"
]
},
{
"Sid": "DenyWithoutGuardrail",
"Effect": "Deny",
"Action": ["bedrock:Converse", "bedrock:ConverseStream"],
"Resource": "*",
"Condition": {
"StringNotEquals": {
"bedrock:GuardrailIdentifier": "arn:aws:bedrock:eu-west-1:123456789012:guardrail/corp-guard-001/version/1"
}
}
}
]
}
¿Qué pasa si el dev intenta invocar un modelo que no está en su lista? AccessDeniedException. ¿Sin guardrail? AccessDeniedException. No hay forma de saltárselo.
El Guardrail que protege todo
Los Guardrails de Bedrock actúan como un firewall semántico. Si el Desarrollador sin querer pega un correo electrónico, numero de documento, un número de tarjeta o hasta una AWS_SECRET_KEY en el prompt, el guardrail lo intercepta antes de que llegue al modelo.
# CDK simplificado
bedrock.CfnGuardrail(self, "CorpGuardrail",
name="corp-ai-guardrail",
sensitive_information_policy_config={
"piiEntitiesConfig": [
{"type": "EMAIL", "action": "ANONYMIZE"},
{"type": "PHONE", "action": "ANONYMIZE"},
{"type": "CREDIT_DEBIT_CARD_NUMBER", "action": "BLOCK"},
{"type": "AWS_ACCESS_KEY", "action": "BLOCK"},
{"type": "AWS_SECRET_KEY", "action": "BLOCK"},
]
}
)El mecanismo de corte: presupuesto en tokens, no en dólares
Algo que debes de saber: AWS Budgets tiene un retraso de 24 horas para reflejar costos. Si un dev entra en un bucle que quema tokens sin parar, la alerta llega al día siguiente. Para IA generativa, eso es poco real. La solución que vamos a estar haciendo: un Accumulator mediante una simple Lambda que cada 5 minutos suma los tokens consumidos por el equipo (de todos sus Inference Profiles) y publica una custom metric. Una alarma de CloudWatch monitorea esa métrica y dispara el corte.
Código (resumido)
# Lambda: Accumulator (se ejecuta cada 5 min)
def handler(event, context):
for team_name, profile_arns in TEAM_PROFILES.items():
total_tokens = 0
for profile_arn in profile_arns:
for metric in ["InputTokenCount", "OutputTokenCount"]:
response = cloudwatch.get_metric_statistics(
Namespace="AWS/Bedrock",
MetricName=metric,
Dimensions=[{"Name": "InferenceProfileArn", "Value": profile_arn}],
StartTime=month_start,
EndTime=now,
Period=86400 * 31,
Statistics=["Sum"],
)
for dp in response["Datapoints"]:
total_tokens += int(dp["Sum"])
# Publicar acumulado MTD como custom metric
cloudwatch.put_metric_data(
Namespace="Custom/BedrockGovernance",
MetricData=[{
"MetricName": "TokensMTD",
"Dimensions": [{"Name": "Team", "Value": team_name}],
"Value": total_tokens,
"Unit": "Count",
}],
)¿Y que va pasar cuando esta alarma se active? Tendremos otra Lambda que le inyectará al profile del equipo que corresponda una política para bloquear cualquier acceso a LLMs.
# Budget Cut Lambda, tarda en hacer efecto en ~10-30 segundos, mucho más rapido que las 24hs de AWS Budgets
def _cut_access(team_name, role_name):
iam.put_role_policy(
RoleName=role_name,
PolicyName="BudgetExceeded-AutoDeny-Bedrock",
PolicyDocument=json.dumps({
"Version": "2012-10-17",
"Statement": [{
"Effect": "Deny",
"Action": ["bedrock:Converse", "bedrock:ConverseStream"],
"Resource": "*",
}]
}),
)Limitaciones, mejoras:
El día 1 de cada mes, lo ideal es que un EventBridge scheduled rule remueve la Deny policy y el equipo arranca de nuevo.
Si tienes alguna forma automatizada que genera las políticas en base a tu directorio activo se debe considerar este cambio.
¿Cómo tendrá que llamar a un modelo un Dev?
ejemplo simplificado
import boto3
session = boto3.Session(profile_name="backend-devs")
client = session.client("bedrock-runtime", region_name="eu-west-1")
response = client.converse(
modelId="arn:aws:bedrock:eu-west-1:123456789012:inference-profile/team-backend-anthropic",
messages=[{"role": "user", "content": [{"text": "Explica qué es un VPC en AWS"}]}],
inferenceConfig={"maxTokens": 256}, // Los parametros que necesitemos
guardrailConfig={"guardrailIdentifier": "corp-guard-001", "guardrailVersion": "1"},
)
print(response["output"]["message"]["content"][0]["text"])Lo importante es que los Devs tiene la herramienta disponible desde el día 0. No tiene que esperar a que se apruebe un presupuesto, a que alguien le cree una cuenta en OpenAI, ni a que se despliegue un proxy. Usa sus credenciales de AWS como viene utilizando para el resto de servicios.
¡Lo logramos!
Ya con estos pequeños cambios podemos tener la trazabilidad del consumo dado por el equipo usando un inference profile.
Esto era para el día 0 y.. ¿ para el resto?
Trade-offs del enfoque nativo
Limitaciones:
El corte es por equipo, no por usuario: Si un dev consume demasiado, se corta a todo el equipo. ¿Cómo se resuelve? Habilitar Model Invocation Logging + métricas per-user
Hay una ventana de aprox 5 min sin protección: El accumulator evalúa cada 5 min, en ese intervalo se pueden consumir tokens. ¿Cómo se resuelve? Con
maxTokenslimitado y la latencia de Bedrock, el impacto máximo es aprox $0.80 y no $200Vendor lock-in con boto3: El código está acoplado a AWS, En una segunda etapa, Bedrock API Key + OpenAI SDK compatible da portabilidad
Inference Profile ARN en el código: El dev no puede poner el model ID directamente. ¿Cómo se resuelve? Una variable de entorno
BEDROCK_PROFILEresuelve esto.No hay dashboard de self-service: El dev no puede ver su consumo sin pedir al Platform Team. Mejora futura: dashboard por equipo con acceso read-only
Novedades en este 2026
Proxy real (LiteLLM o similar): Cuando la organización crezca y necesite soporte multi-provider (OpenAI, Anthropic, Azure), un proxy centralizado sobre ECS/Fargate con virtual keys, caching, y observabilidad avanzada es el camino. Pero no es lo que necesitas el día 1.
OpenTelemetry + Langfuse: Para organizaciones que despliegan agentes autónomos (no solo prompts simples), la observabilidad semántica con trazas jerárquicas es esencial. Esto permite ver el Tree of Thoughts o ToT del agente y hacer forense cuando algo sale mal. De vuelta, es una evolución, no un prerequisito.
Observabilidad per-user: Model Invocation Logging (solo metadata, sin capturar el contenido del prompt por privacidad) permite crear métricas por usuario SSO. Así detectas quién es el power user dentro de un equipo, sin cortar a todos.
NEW 2026: Costos por usuario usando tags directamente en Bedrock. Amazon Bedrock ahora admite la asignación de costos por entidad principal de IAM, como usuarios y roles de IAM, en AWS Cost and Usage Report 2.0 (CUR 2.0) y Cost Explorer. Esto permite a los clientes comprender y atribuir los costos de inferencia de modelos de Bedrock a usuarios, equipos, proyectos y aplicaciones.
https://aws.amazon.com/es/about-aws/whats-new/2026/04/bedrock-iam-cost-allocation/
Conclusiones
La industria está creando herramientas para que sus empleados puedan utilizar IA. Ya no se trata de crear herramientas para la autogestión únicamente — ahora la idea es que los propios colaboradores dentro de una organización puedan usar estas herramientas. Y eso está bien.
Pero debemos darles acceso con gobierno real. No después, no cuando ya haya un incidente, no cuando la factura ya sea inmanejable, similar a lo que en seguridad se conoce como el zero-day.
Y lo bonito de todo esto es que si ya sabes gestionar políticas de IAM, SCPs y credenciales SSO en AWS... ya sabes hacer esto. No necesitas ser un ingeniero de Machine Learning. No necesitas desplegar tu propio modelo. Se trata de saber qué herramientas tienes y cómo puedes seguir aportando al equipo donde estás.
Las herramientas cloud que ya dominas son la base para gobernar la IA que viene. Los especialistas dentro del mundo cloud somos nosotros.
¿Te gustaría que estemos en 📩 contacto?
Héctor Fernández
AWS Community Builder
https://blog.hectorfernandez.dev




